
Understanding Bazel remote caching
A deep dive into the Action Cache, the CAS, and the security issues that arise from using Bazel with a remote cache but without remote execution


The previous article on Bazel action non-determinism provided an introduction to actions: what they are, how they are defined, and how they act as the fundamental unit of execution in Bazel. What the article did not mention is that actions are also the fundamental unit of caching during execution to avoid doing already-done work.
In this second part of the series, I want to revisit the very basics of how Bazel runs actions and how remote caching (not remote execution, because that’ll come later) works. The goal here is to introduce the Action Cache (AC), the Content Addressable Storage (CAS), how they play together, and then have some fun in describing the many ways in which it’s possible to poison such a cache in an accidental or malicious manner.
The Action Cache (AC)
Picture this build file with two targets that generate one action each:
genrule(
name = "foo",
outs = ["foo.txt"],
cmd = "sleep 5; echo foo >$@",
)
genrule(
name = "bar",
outs = ["bar.txt"],
srcs = [":foo"],
cmd = "sleep 5; { cat $< ; echo bar; } >$@",
)And now this sequence of commands:
bazel build //:bar: This first command causes Bazel to build//:bar, possibly from scratch. This takes at least 10 seconds due to thesleepcalls we introduced in the commands. As a side-effect of this operation, Bazel populates its in-memory graph with the actions that it executed and the outputs they produced.bazel build //:bar: This second command asks Bazel to do the same build as the first command and, because we just built//:barand Bazel’s in-memory state is untouched, we expect Bazel to do absolutely nothing. In fact, this command completes (or should complete) in just a few milliseconds due to Bazel’s design.bazel shutdown: This third command shuts the background local Bazel server process down. All in-memory state populated by the first command is lost.bazel build //:bar: This fourth command asks Bazel to do the same build as the first and second commands. We didn’t run abazel cleanso all on-disk state is still present, so we should expect Bazel to not rebuild//:foonor//:bar. And indeed they are not rebuilt: Bazel also “does nothing” like in that second command (thesleeps don’t run), but the build is visibly slower in this case.
The problem or, rather, question is… how does Bazel know that there is nothing to do on that fourth command? A system like Make would discover that all output files are “up to date” by comparing their timestamps against those of their inputs, but remember that Bazel tracks output staleness by inspecting the content digests of the inputs and ensuring they haven’t changed.
Enter the Action Cache (AC): an on-disk persistent cache that helps Bazel determine whether the outputs of an action are already present on disk and whether they already have the expected (up-to-date) content. The AC lives under ~/.cache/bazel/_bazel_${USER?}/${WORKSPACE_HASH?}/action_cache/ and is stored in a special binary format that you can dump with bazel dump --action_cache.
Conceptually, the AC maps the ActionKeys that we saw in the previous article to their corresponding ActionResults. In practice, the AC keys are a more succinct representation of the on-disk state of the inputs to the action: up until Bazel 9, the keys were known as “digest keys” but things have changed recently to allow Bazel to better explain why certain actions are rebuilt; the details are uninteresting in this article though.
But what is an ActionResult? The “action result” records, well, the side-effects of the action. Among other things, the ActionResult contains:
The exit code of the process executed by the action.
A mapping of output names to output digests.
The mapping of output names to digests is the piece of information I want to focus on because this is what allows the fourth Bazel invocation above to discover that it has “nothing to do”. When Bazel has lost its in-memory state of an action, Bazel queries the AC to determine the names of its outputs. If those files exist on disk, then Bazel can compute their digests and compare those against the digests recorded in the ActionResult. If they match, Bazel can conclude that the action does not have to be re-executed.
And this explains why the fourth Bazel invocation is visibly slower than the second invocation, even if both are “fully cached”: when the in-memory state of an action is lost, Bazel has to re-digest all input and output files that are on disk, and these are slow operations, typically I/O-bound. If you have seen annoying pauses with the checking cached actions message, you now know what they are about.
Introducing remote caching
The AC is, maybe surprisingly, a concept that exists even if Bazel is not talking to a remote cache or execution system. But what happens when we introduce a remote cache into the mix?
First of all, the remote cache needs to be able to answer the same questions as the local AC: “given an action key, is the action result already known?” But let’s think through what goes into the result of such a query. Does the remote AC capture the same information that goes into a local ActionResult, or does it do something different?
Given that we are talking about a remote cache, it’s tempting to say that the value of the cache entry should embed the content of the output files: after all, if Bazel scores a remote AC hit, Bazel will need to retrieve the resulting output files to use them for subsequent actions, right? Not so fast:
What if Bazel already has the output files on disk but is just querying the remote AC because the local in-memory state was lost? In this case, you want the response from the cache to be as small and quick as possible: you do not want to fetch the output contents again because they may be very large.
What if you (the user) don’t care about the output’s content? Take a look at the actions in the example above: if all of them are cached, when I ask Bazel to build
//:barI probably only want to downloadbar.txtfrom the remote cache. I may not care about the intermediatefoo.txt, so why should I be forced to fetch it when I query the cache just to know if//:foois known?What if I'm using remote execution and I'm building and running a test? The test runs remotely, so the local machine does not need to download any file at all!
This is why the ActionResult, even for the remote AC, does not contain the content of the outputs.
But then… how is the remote cache ever useful across users or machines, or even in a simple sequence like this?
bazel build //:bar
bazel clean
bazel build //:barThe bazel clean in between these two builds causes all disk state (the local AC and the local output tree) to be lost. In this situation, Bazel will leverage the remote AC to know the names of the output files and their digests for each action… but if those outputs are not present on the local disk anymore, then what? Do we just rebuild the action? That’d… work, but it’d defeat the whole purpose of remote caching.
Enter the Content Addressable Storage (CAS), another cache provided by the remote caching system to solve this problem. The CAS maps file digests (not names!) to their contents. Nothing more, nothing less. By leveraging both the AC and the CAS, Bazel can recreate its on-disk view of an already-built target by first checking with the AC what files should exist and then leveraging the CAS to fetch those files.
Let’s visualize everything explained above via sequence diagrams.
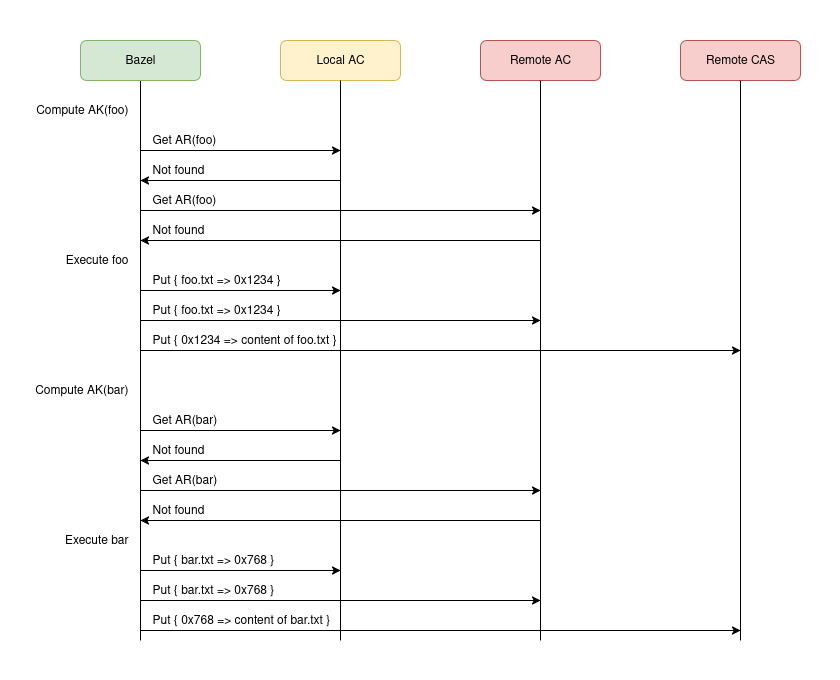
This first diagram represents the initial bazel build //:bar invocation, assuming that //:bar has not been built at all by anyone beforehand. This means that Bazel will not be able to score any local nor remote AC hits and therefore will have to execute all actions:
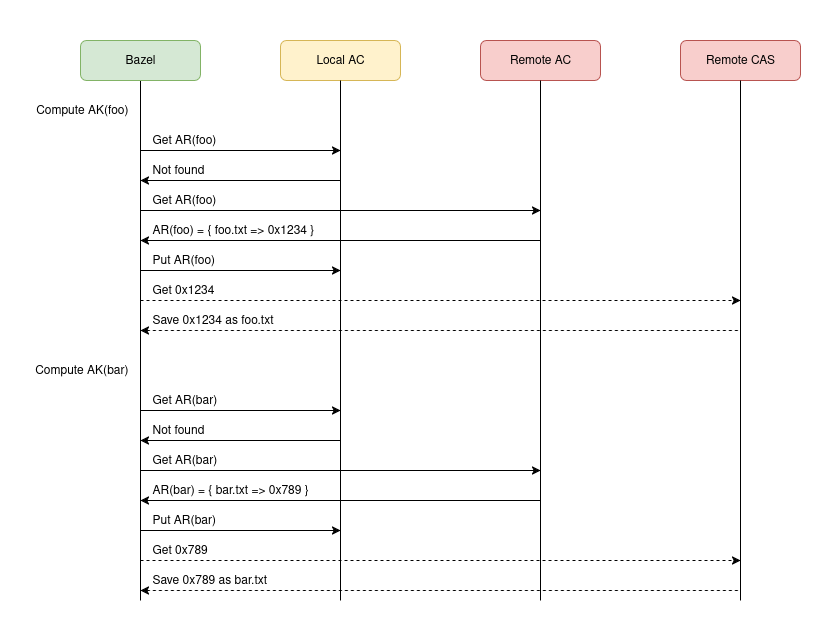
This second diagram represents the second bazel build //:bar invocation executed after bazel clean. In this case, all local state has been lost, but Bazel is able to score remote cache hits and recreate the local disk state by downloading entries from the remote AC and CAS. The dashed lines against the CAS represent optional operations, controlled by the use (or not) of the “Build Without The Bytes” feature.
Before moving on to the fun stuff, a little subtlety: whenever the AC and CAS use digests, they don’t just use a hash. Instead, they use hash/size pairs. This adds extra protection against length extension attacks and allows both Bazel and the remote cache to cheaply detect data inconsistencies should they ever happen.
Let’s poison the cache
With any remote caching system, we must fear the possibility of invalid cached entries. We have two main types of “invalid entries” to worry about:
Actions that point to results that, when reused, lead to inconsistent or broken builds. This can happen if the cache keys fail to capture some detail of the execution environment. For example: if we have different glibc versions on the machines that store action results into the remote cache, we can end up with object files that are incompatible across machines because the glibc version is not part of the cache key.
Actions that point to malicious results injected by a malicious actor. The attack vector looks like this: a malicious actor makes a
CppCompileaction point to a poisoned object file that steals credentials and uploads them to a remote server. This object file is later pulled by other machines when building tools that engineers run or when building binaries that end up in production, leading to the compromised code spreading to those binaries.
Scary stuff. But can this attack vector happen? Let’s see how an attacker might try to compromise the remote cache.
If the attacker can inject a malicious blob into the CAS, we now have a new entry indexed by its digest that points to some dangerous file. But… how can we access such file? To access such file, we must first know its digest. Bazel uses the digests stored in the AC to determine which files to download from the CAS so, as long as there is no entry in the AC pointing to the bad blob, the bad blob is invisible to users and is not used. We have no problem here.
The real danger comes from an attacker having write access to the AC. If the attacker can write arbitrary entries to the AC, they can pretty much point any action to compromised results. Therefore, the content of the AC is precious.
Protecting the remote cache
In order to offer a secure and reliable remote cache system, we must restrict who can write to the cache. And because we can’t control what users do on their machines (intentionally or not), the only option we have is to restrict writes to the AC to builds that run on CI. After all, CI is a trusted environment so we can assume attackers cannot compromise it.
But that’s not enough! Attackers can still leverage a naive CI system to inject malicious outputs into the cache. Consider this: an attacker creates a PR that modifies the scripts executed by CI. This change leverages the credentials of the CI system to write a poisoned entry into the AC. This poisoned entry targets an action that almost-never changes (something at the bottom of the build graph) to prevent it from being evicted soon after. The attacker runs the PR through CI and then deletes the PR to erase traces of their actions. From there on, the poisoned artifact remains in the cache and can be reused by other users.
Yikes. How do we protect against this? The reality is that we just cannot, at least not in a very satisfactory way. If the CI system runs untrusted code as submitted in a PR, the CI system can be compromised. We can mitigate the threat by doing these:
For CI runs against PRs (code not yet reviewed and merged):
Disallow running the CI workflows if the changes modify the CI infrastructure in any way (CI configurations, scripts run by CI, the Bazel configuration files, etc.)
Configure Bazel with
--noremote_upload_local_resultsso thatgenrules or other actions that could produce tampered outputs cannot propagate those to other users.
For CI runs against merged code:
Configure Bazel with
--remote_upload_local_resultsso that they are the only ones that can populate the remote cache. If there is any malicious activity happening at this stage, which could still happen via sloppy code reviews or smart deceit, at least you will be able to collect audit logs and have the possibility of tracing back the bad changes to a person.
This configuration should provide a reasonably secure system at the expense of slightly lower cache hit rates: users will not be able to benefit from cached artifacts until their code has been merged and later built by CI. But… doing otherwise would be reckless.
Before concluding: what about the CAS? Is it truly safe to allow users to freely write to the CAS? As we have seen before, it is really difficult for a malicious entry in the CAS to become problematic unless it is referenced by the AC. But still, we have a couple of scenarios to worry about:
DoS attacks: Malicious users could bring the remote cache “down” (making it less effective) by flooding the CAS with noise, pushing valid artifacts out of it, or by exhausting all available network bandwidth. This is not a big concern in a corporate environment where you'd be able to trace abusive load to a user, but you might still run into this due to accidental situations.
Information disclosure: If a malicious user can somehow guess the digest of a sensitive file (e.g. a file with secrets), they could fetch such file. So… how much do you trust cryptography?
Next steps
As presented in this article, deploying an effective remote cache for Bazel in a manner that’s secure is not trivial. And if you try to make the setup secure, the effectiveness of the remote cache is lower than desirable because users can only leverage remote caching for builds executed on CI: any builds they run locally, possibly with configurations that CI doesn’t plan for, won’t be cached.
The only way to offer a truly secure remote caching system is by also leveraging remote execution. But we’ll see how and why in the next episode.
As always Julio great article, about the remote cache, the protocol is only efficient if you can use the grpc protocol and not the plain http, as gprc allows to match multiple files on a single transaction, while http/rest needs to be done file by file
This article comes at a great time for me, I'm literally trying to set up a remote cache without RBE this week.